Have you ever wondered what your friends at tech companies do? Imagine the following…
Book Inc. is a company that publishes a novel (piece of software). The company wants to continuously improve their book, so they release a new, updated version every few weeks (agile methodology). The novel is twenty chapters long, so the company decides to break up the work (because teamwork makes the dream work, right?).
The company has four teams (development teams). Team 1 is in charge of Chapters 1-5, Team 2 is in charge of Chapters 6-10 and so on. The company has the main copy of the book (master branch) in a Word doc on one computer in the company headquarters (code repository). The company e-mails a copy of the word doc to each team’s shared computer (feature branch).
Each team has four writers (developers) and one team leader (project manager). The leader and the writers work together in meetings (backlog grooming) to decide which parts of the book they will fix for this release period (sprint). The project manager, from the team’s shared computer, forwards the copy of the book (local branch) to each of the writers.
The writers spend a couple weeks making edits to the book (development/construction). They have to make sure that they talk to each other so that the team’s chapters make sense. To coordinate, they meet every morning before work (scrum/stand-up meeting) and tell each other what they did yesterday, what they’ll do today, and if they are having any problems figuring out what to write. The team leader will figure out ways to help the writers if they have writer’s block or if they need more information about what to write.
Some teams may feel that their chapters need to be in a certain language (programming language). “It just reads better in the original Italian, of course!” The teams just need to keep in mind what languages the user is able and willing to read. Some languages are better at expressing certain things than other languages, so it may be necessary to use different languages. Usually, it’s easier to just use the same one.
When the writers are ready, they email their work back to the team’s shared computer and work to make sure all of the edits fit together (merging a local branch to a feature branch). The team then prints out the new copy and binds it into a book (creating a build).
They then give the book to a group of editors (QA team) that makes sure everything is spelled correctly. When the editors are happy, they give the book to some special readers from the company who are story telling specialists (user acceptance testers). While the editors checked for grammar, these readers make sure the story will be entertaining to the public. “Why is the sad man sad? Does everyone have to die at the end? Can’t we really just wrap this all up with a dream sequence?”. If there are any changes that need to be made, the writers have to type up the fixes and print out another book.
Once all the editors and readers are happy, the team emails their version of the book to the main computer in the company headquarters. The teams have to coordinate again to make sure all of the edits work together (merging feature branches to the master branch). Then the editors and readers make sure that all of the team’s work makes sense when it’s added all together (integration testing). They’ll also check to make sure if this book is better than the last version of the book (regression testing).
Once everybody is satisfied, the company prints and binds the book from the main computer. They make a lot of copies because there are several book stores (servers) that will sell the book! The team spends all night loading the books into trucks, unloading the books into the store, and making sure they are displayed just right on the shelves (deployment process). The next day, shoppers (users) come to the store to buy the books.
The company has to be very strategic about how the ship out all of the books. In fact, this process (dev ops) is just as important as writing the book! It can be expensive and difficult to print a lot of books and ship to a lot of different stores. It’s easy to ship everything to one store, but what if that store has a flood (server hardware failure)? What if so many people show up to the book store that the book store can’t fit everybody in (failure from high traffic)? It would be a good idea to send the books to a few stores (distributed computing) and have employees (load balancers) that tell shoppers to go to another store if one runs out of books or if another is too crowded.
Meanwhile, the writers all get together to figure out what went well and what didn’t go so well during the past few weeks (sprint retrospective). They write down their lessons learned (knowledge management) and quickly start work on the next version of the book!
The Technical Version of the Story
In the agile methodology, organizations focus on continuous improvement by releasing new features, updates, and bug fixes over the course of a sprint. A sprint is a period of time that includes development, testing, and deployment activities and lasts usually few weeks (or a few days for very advanced organizations).
Development teams create feature branches off of the master branch in the code repository. Individual developers create their own local branches from the feature branch. The team then meets for a backlog grooming meeting to determine what tasks will be completed during the sprint.
Development teams have daily stand-up meetings to ensure accountability and give project managers the ability to remove blocking issues from the team’s path. Once a team has completed their construction phase, they merge the local branches back into the feature branch and create a build of the software. They deploy this build to a QA or testing environment for QA testing. After passing QA testing, business users validate the business logic during user acceptance testing.
Once a build has passed testing, the team merges their feature branch back into the master branch. The testing team will perform integration and regression tests in a staging environment to ensure that all of the teams’ code behaves as expected.
After passing the last round of testing, the team deploys the code from the master branch into production. Organizations follow a set of deployment procedures designed by the dev ops team to ensure that all the code is deployed with the least cost possible. Organizations may also deploy code across different servers and utilize load balances to prepare for scenarios when individual servers are overloaded or fail.
At the end of the sprint, the team has a retrospective to discover how they can improve in the future, and then the process begins all over again.

























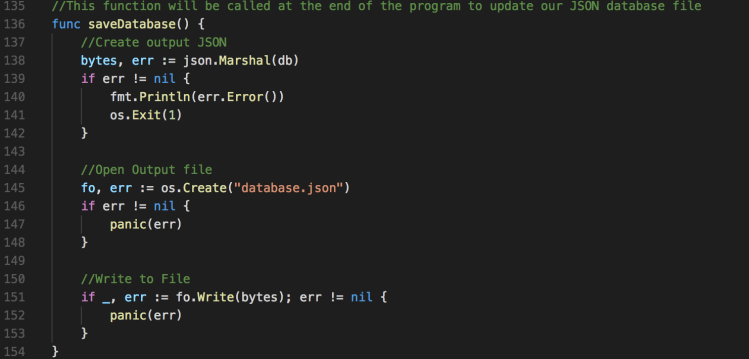
 To read our file, we use the ioutil package. We can take the result and use the Unmarshal function. Unmarshal will deserialize the JSON from a byte array into a structure that you define. In this case, it will deserialize into our db variable of type Database
To read our file, we use the ioutil package. We can take the result and use the Unmarshal function. Unmarshal will deserialize the JSON from a byte array into a structure that you define. In this case, it will deserialize into our db variable of type Database